Bridging on a budget
Over the last few months, instead of adding new features to Bridgy Fed or Bounce, I’ve been focusing on cost cutting. It’s not fun, exactly. I’d rather be building new things! But we’re a non-profit, surviving on grants and individual donations from people who don’t have a lot to spare. When you all give us your hard-earned money, we feel a deep responsibility to use it as well, and as efficiently, as possible.
So we optimize, we cut, and we stretch every dollar as far as we can. Over the past two years or so, we’ve managed to cut our serving costs 5x, from ~$0.15 per active user per month to ~$0.03. Over that same period, our user base grew by 75x, we rearchitected to handle that growth, and we shipped a ton of new features that significantly increased our load. So, I’m proud of that cost reduction.
It didn’t happen all at once, though. We’ve made four major passes over the last two years, each more difficult than the last. We started by adding caches and dropping some unnecessary work, and by the end we were doing a live datastore migration and switching from client SDKs to raw bytes on the wire.
Here’s the tour.
Hello? Is this thing on?
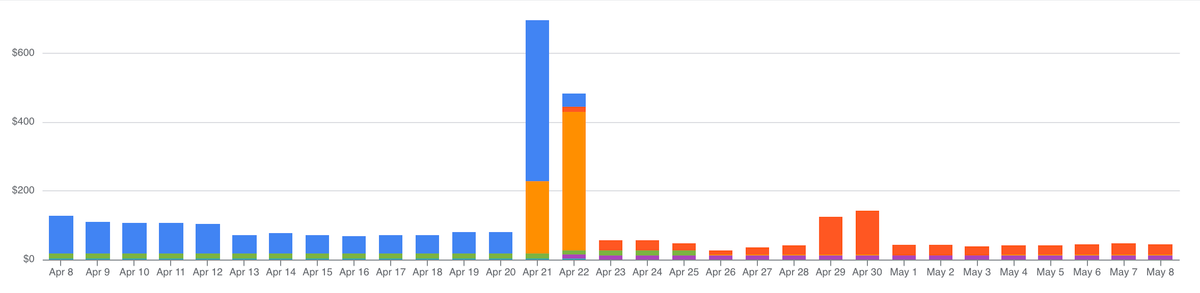
We first started looking at costs in March 2024. Datastore reads dominated our bill, but I didn’t understand why. We were already caching pretty aggressively in memcache, so most of those reads should have been cache hits, but they weren’t.
I turned on Datastore audit logging, piped a day of it into BigQuery, and started running queries against 37M traces. The answer was clear. Lookups were dominated by DID documents, which we weren’t caching due to a bug in our ndb context. Also, a majority of our queries were mapping between bridged posts in different networks, which were easy to cache manually.
Combined, those two fixes cut our datastore reads by 5-10x. We also pruned down our logging a bit and turned off some other heavy endpoints. Overall, the investigations here took some work, but the solutions were quick and straightforward.
YAGNI
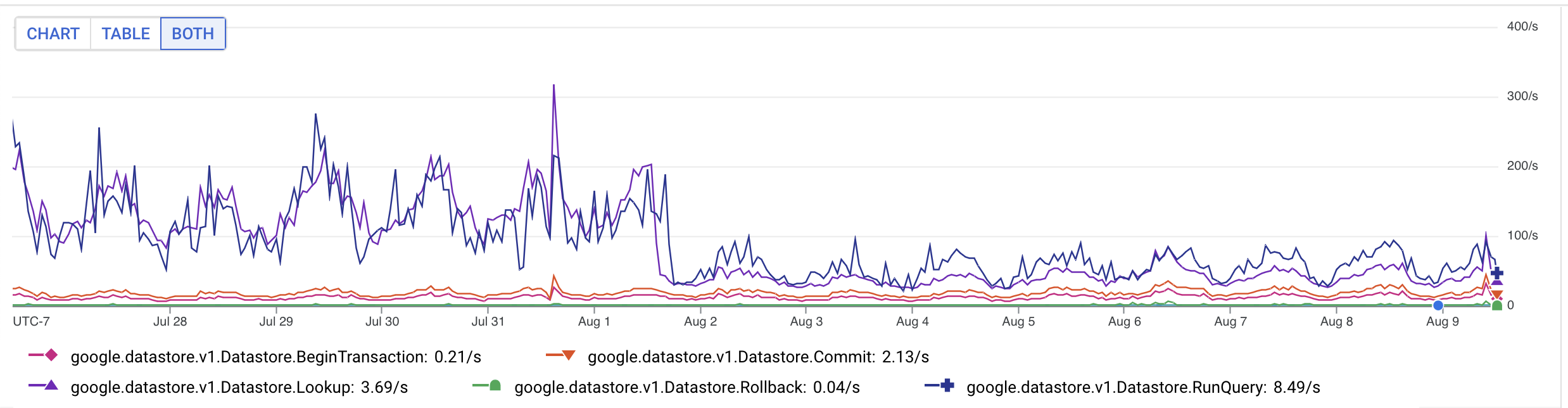
That held us until December 2024, when datastore writes started adding up and brought us back. Two big projects came out of this pass.
First, we stopped storing transient activities. Our object model is based on ActivityStreams, and we’d been persisting every activity we received, including transient CRUD activities that we never needed again. I stopped storing those, and our datastore writes immediately dropped by half.
Next, I looked at deletes. When we received a Delete, we tombstoned the object by set its deleted flag to true. That’s often good practice, but in our case, it never actually bought us anything, just a pile of dead rows that cost us to store and index. It also didn’t match user expectations: when users delete something, they generally want it to be deleted for real, not just hidden. So, I switched our code to actually delete, then ran a Dataflow job to clean up the backlog of 18M tombstoned objects. I then made transient activities automatically expire, which knocked out tens of millions more.
The final bit of write load was that we were tracking our activity deliveries to each fediverse inbox. That was a nice user-visible feature early on, while Bridgy Fed was small, but as we grew, it just wasn’t pulling its weight any more. So, I dropped it.
This pass kept our costs stable for a year. It was a good year! But it couldn’t last forever; by December 2025, we were back at the well.
Every time you scale up 10x
Bridgy Fed serves all of its ATProto events over a firehose. ATProto firehoses are modeled after Kafka streams: each event includes a monotonically increasing sequence number. This is one of the few points of serialization in the protocol: all of a PDS’s events have to be serialized on its firehose, in order.
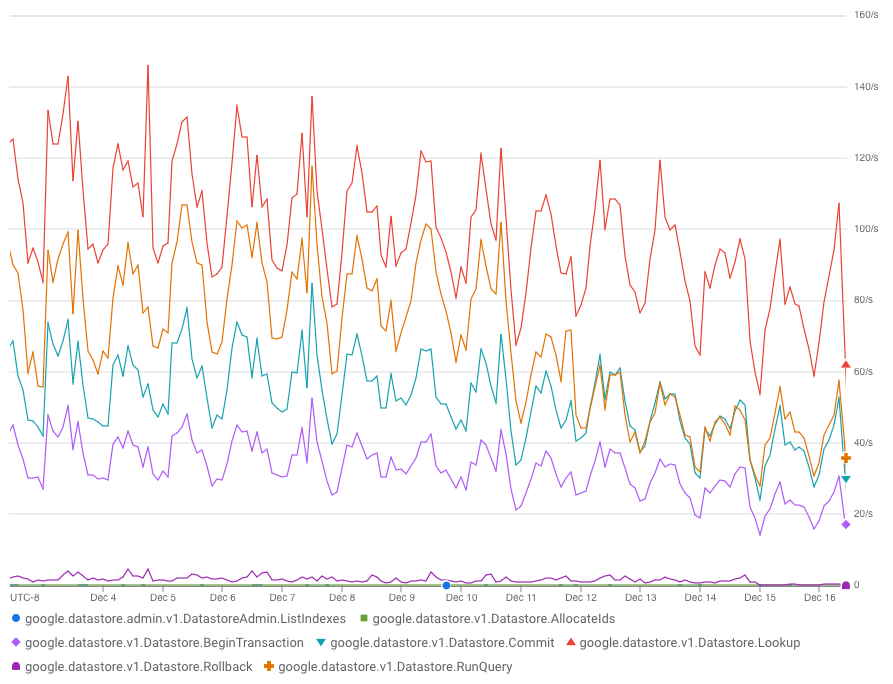
Initially, we allocated sequence numbers the naive way: one by one, out of the datastore, transactionally. This worked ok for a while, until it didn’t. Firestore can handle up to 10qps or so of transactional writes to a single entity, but above that we started to see contention (more details), regardless of whether we used optimistic or pessimistic locking. At peak times, this built up our task backlog enough that we started dropping activities entirely. The additional task retries and datastore load also significantly increased our costs. Not ok.

The fix was to move sequence number allocation somewhere cheaper, out of the datastore. Memcache was the obvious answer, backed by the datastore in batches, but it wasn’t an easy change. Building it was delicate; deploying it, more so. I ran it in shadow writes mode for several days, testing it by flushing memcache and injecting failures to check that it never violated the most important constraint: sequence numbers can’t go backward. I knew the migration would be delicate and risky, so I wrote a comprehensive playbook and tested and practiced offline before I finally ran it in production. Brought back memories of doing big failovers and migrations at Real Jobs™️.
Fortunately, it worked. Contention and costs quickly dropped back down. Phew.
Eff it, we're going to five one region
Redesigning our sequence allocation may have been necessary, but it wasn’t sufficient. A few months later, we were back, trying to hold down costs again.
We’d known for years that we were paying too much for the datastore. It was multihomed across multiple regions, which gave us marginally better availability and durability, but it cost twice as much as a single region. Ugh.
The catch was, we couldn’t just switch to a single region in place. We’d need to make a whole new single-region datastore, copy the data to it, and then migrate to it. Unfortunately, we had ~700M rows, ~2.3TB of data, and an always-on service doing ~10-20k IOPS. Migrating would be a huge endeavor.
So I’d deprioritized it, and we found other ways to cut instead. But this time, I’d run out of rabbits to pull out of hats, the datastore still constituted a majority of our costs, and we were still overpaying. It was time to bite the bullet and migrate.
First, we had to figure out how to copy the data. The simplest answer was to take downtime, copy everything over, then switch. That would work, but we’d lose fediverse activities and webmention that arrived while we were down. Not great.
The next approach was to enqueue incoming activities in our task queue, let them collect there, and then handle them once we were back up. We’d pause bridging during the copy, and turn off datastore writes entirely, but continue to serve reads. All we had to do was clean up our activity and webmention handlers a bit to make sure they never wrote to the datastore.
I still worried, though. How long would it take to copy ~10B total rows (including indices) and 2.3TB of data? The docs didn’t say, nor did the forums. Could we tolerate pausing bridging for an hour? Sure. A day? Maybe. A week? Almost certainly not. And we didn’t know which it would be.
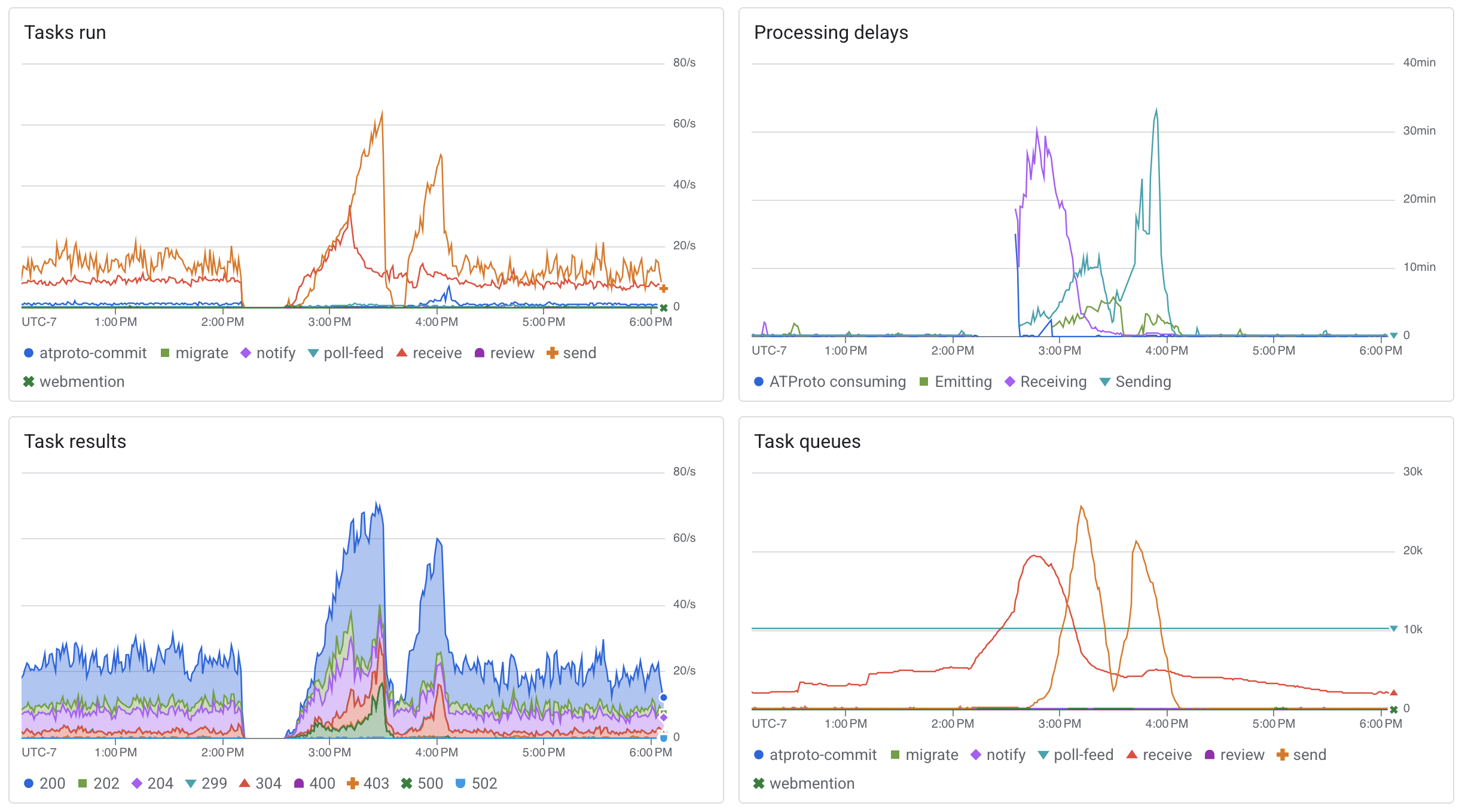
So, I moved on to our final approach: do the initial copy in the background, while we were still up and bridging and writing new data. Then, switch to read only and copy over the remaining window of new writes. I figured there would be a Dataflow template for this, but none of them worked – we needed to filter by arbitrary queries, not just kinds – so I ended up writing my own.
That was just the beginning, though. Getting this right without losing data or breaking anything would be a complicated, delicate operation. We needed to implement a new read-only mode, do the big copy, switch the db to read only, pause task queues, flush memcache, do the catch-up copy, run smoke tests and sanity checks to make sure everything made it over, point our services to the new db, check that our firehose consumer and server didn’t go backward, reload memcache, and then bring everything back up and start bridging again. All while going as fast as possible in order to minimize the critical section. Phew.
Fortunately, again, Anuj and I have done these kinds of big, sensitive operations before at Real Jobs™️, so I felt comfortable doing the prep, writing the playbook, practicing everything, and then running it for real.
Of course, nothing this complicated goes perfectly. We discovered at the last minute that backup/restore is region-locked, so we had to use the slower, pricier export/import instead. And we missed copying a few blocks in the first pass, so we had to spend 20 minutes extra finding and rescuing them.
Still, we ended up paused for only 45 minutes total, which felt ok. And the migration cut our total spend by as much as 40%, which was huge.
The root of all evil
Finishing that migration was a relief, but we weren’t done. Our frontend instance count was way higher than it should have been to serve just ~100qps. It didn’t take long to figure out why: our ATProto getRepo calls were way too slow, 90-120s for larger repos, which was throwing off the autoscaler.
I tried tuning the scheduler, and then tried moving getRepo to a dedicated service with an entirely different config, but no luck. It was just too heavy, in both CPU and IO. Time to break out the profiler and traces!
Thus began a week of profiling and instrumentation, flame graphs, careful optimization, and despair. I eventually managed to crack it, but it was a journey. The key changes:
- Switched loading blocks from
ndb(our ORM) to the raw gRPC API, which cut out all ofndb‘s Python object construction. We now read encoded DAG-CBOR bytes directly off the wire. - Parallelized datastore lookups within each MST level. We were already batching, but we weren’t parallelizing batches yet.
- Replaced our use of pure Python
dag_cborfor serializing and deserializing MST nodes and CIDs with the faster nativelibipld. (Thank you Marshall!)
Overall, these sped up getRepo ~15x, bringing big repos down to just 6s or so, and frontend instances down from ~25 to ~5.
Stop! Strategy time
The end result of all of this is that we grew from 2k users to almost 150k, added a ton of heavy new functionality, and still managed to optimize and cut down costs from $.15 per active user per month to just $.03 or so.
That’s good! We’re happy with it. We could always do more, though. We know the cost floor is even lower: rewrite the whole thing in Go or Rust, run our own database and services ourselves, leave the cloud entirely and rack our own servers in colos, even negotiate our own bandwidth deals.
It’s true, those could be cheaper, notwithstanding the up front cost of buying hardware. Hosting isn’t our only cost, though. Our time is the other, bigger cost. Every hour we’d spend patching OSes, administering Postgres, firefighting Kafka, and driving out to the colo to swap a hard drive is an hour (or 10, or 100) that we wouldn’t spend on Bridgy Fed and Bounce themselves.
Cloud hosting isn’t always cheap. Sometimes it feels like highway robbery. (Don’t get me started on egress pricing.) However, much of that extra cost buys us world-class SREs, hardware ops, security engineers, and more, for pennies on the dollar. For us, at least, that’s good value for money.
Bridgy Fed is a free public service, funded by individual donations and institutional grants. Real people and orgs trust us with their money so that we can keep this thing running. We feel that responsibility acutely, and we’re serious about keeping these projects sustainable for the long haul. Every dollar we don’t spend on hosting is a dollar that keeps us afloat a bit longer.
This post was pretty far down in the weeds. Thank you for reading! If you enjoyed it, or you find Bridgy Fed or Bounce useful, or you just want a less centralized social web, join our Patreon! Every bit helps, and as we hope you can tell, we try hard to make it count.